Prevent & minimize incidents
Incidents are inevitable, but downtime and chaos don't have to be. Resilience is built, not wished for. The best teams prepare, automate, and learn, so when incidents happen, they're ready to bounce back fast.
Why resilience matters
Modern systems are complex. Outages, misconfigurations, and human error are facts of life. The difference between high-performing teams and those that lose trust with their customers? Resilience: the ability to prevent incidents, and to recover quickly when they do occur.
Readiness = prepare + automate + learn
We think resilience is an evergreen initiative, an elusive and unreachable target and not a one-time project. Our most successful customers focus on a 3 part cycle, in which one:
- Prepares: Map your systems, dependencies, and ownership so you know what's important, long before the first incident strikes. Build a meaningful catalog, to assist your human and AI incident responders.
- Automates: Set up proactive checks, alerts, and self-healing workflows. Empower your human and AI incident responders to self-serve their way through investigation, remediation and communication around the incident, without need for tickets or approvals.
- Learns: Capture incident data and feed it back into your processes for continuous improvement. The best teams generate their retrospective documentation and index it to prevent lengthy recurreces of the same incidents (greatly decreasing Mean Time to Resolution). Chase remediation tasks and improve the resilience of the system for a meaningful change to SLOs and MTBF (Mean Time Between Failure)
A focus on learning from the past and a culture of continuous improvement can switch your teams from being reactive and overburdened to proactive and confident.
How to build resilience with Port
Prepare: map your world
A clear, up-to-date software catalog is the foundation of resilience. Know what you have, who owns it, and how everything connects.
Start building your software catalog
Some of the data you should be cataloging, to prepare for the incidents to come:
- Services - all the internal services that R&D owns, from code to cloud. Map the source repositories,
- Ownership - every service should be owned, and the ownership should be clear for anyone to observe. The good news is that with our ownership inheritance, you can take the ownership from a service and inherit this across the graph of all related entities in your catalog
- Environments - it's important to account for all places that the code can run! Not just development, staging and production. Model every tenant. Make sure that there is no place the code can run (or fail), that isn't modelled and governed by Port
- Features - model your features and feature flags, to assist your human and AI agents with understanding the impact of incidents in terms of features, or the possibility of using feature flags to remediate issues during investigation
- Customers - track your customers, their access to different environments, features and entitlements
Take a look at what's possible when everything is connected. Here's a real world example from a customer using our MCP server:

Track: monitor the metrics that matter
Many of our customers leverage Mean Time to Recovery as a golden metric for incident management. We recommend tracking MTTR, along with all the DORA metrics, but not stopping there.
Some teams become really adept at closing our incidents quickly, and engineering leadership becomes interested in focusing on improving technical debt associated with the flakiest components in the system. Tracking the Mean Time Between Failures (MTBF) can be a great metric to show the operational point in time and historical health of each component.
Automate: proactive checks and self-healing
Don't wait for things to break. Use Port to automate health checks, enforce best practices, and trigger remediation workflows before users are impacted.
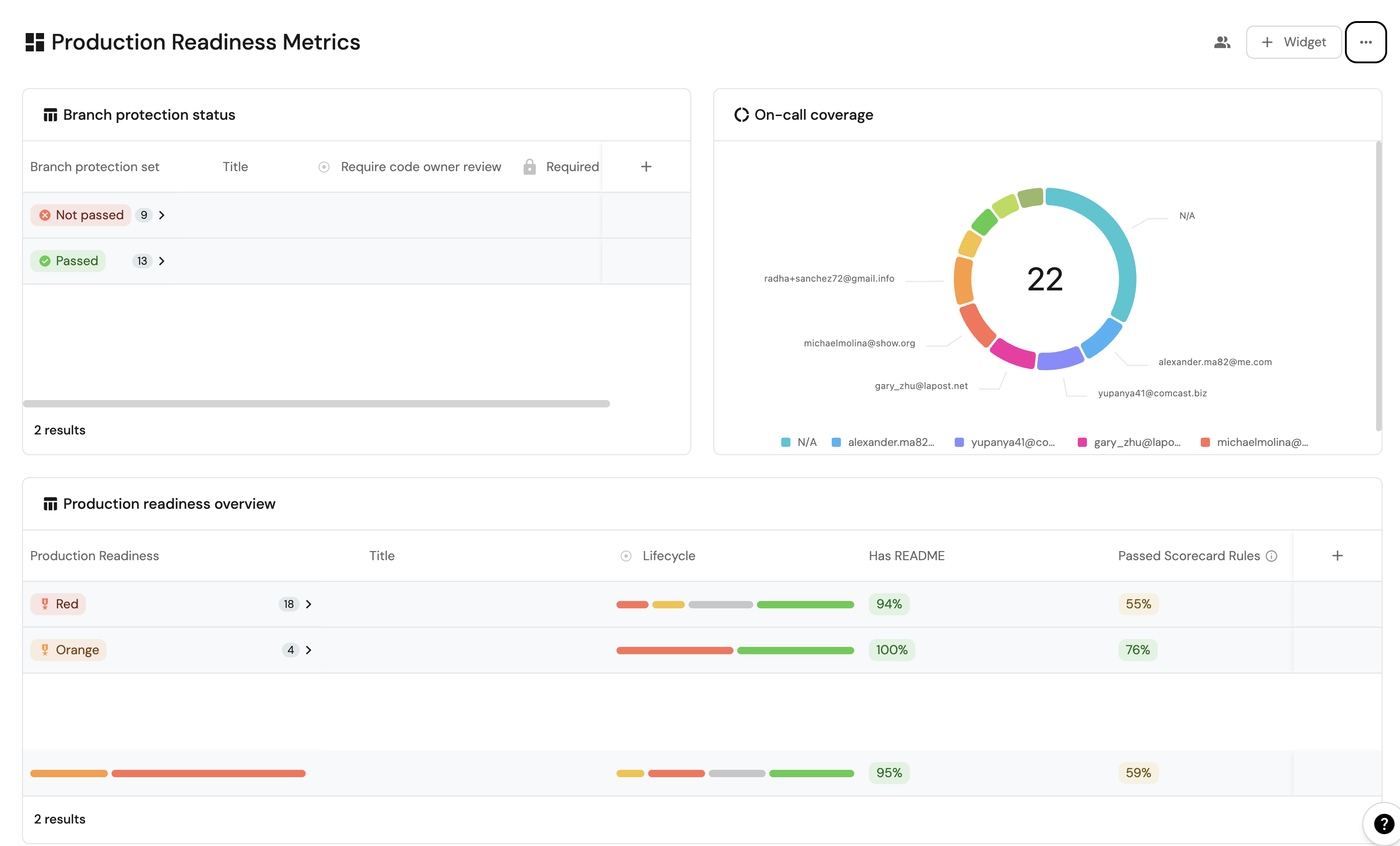
Scorecards
Scorecards allow your central governance functions to define what good looks like for all non-functional aspects of software development. AppSec teams can create Application Security scorecards, SRE teams can define Reliability scorecards and your Platform teams can create scorecards around the needs of the development platform (Ownership, Tagging, Pipeline Health, Supply Chain Health).
Our most successful customers define Production Readiness scorecards. Think about Production Readiness as almost a breadth-first approach to covering many needs across a variety of scorecards. Production Readiness for example:
- may not include all layers of an Application Security scorecard, but it may include a check that security tools are configured and that there are no critical vulnerabilities
- may not include all expectations of an Ownership scorecard, but may enforce an expectation that the service being deployed has an owning team configured
- may not include all rules from a Reliability scorecard, but may enforce the presence of one availability SLO for the service being deployed
Leverage a Production Readiness scorecard to make sure that your incident response teams have covered the baseline needs of what will be required to respond to an incident.
Track SLOs and SLIs
Beyond Production readiness and other deeper, more specialized scorecards, consider tracking all SLOs and SLIs for your services in Port, for a better view of your Reliability posture. Configure the AI Incident Manager Agent to assist with exploring and learning from the incidents from the past.
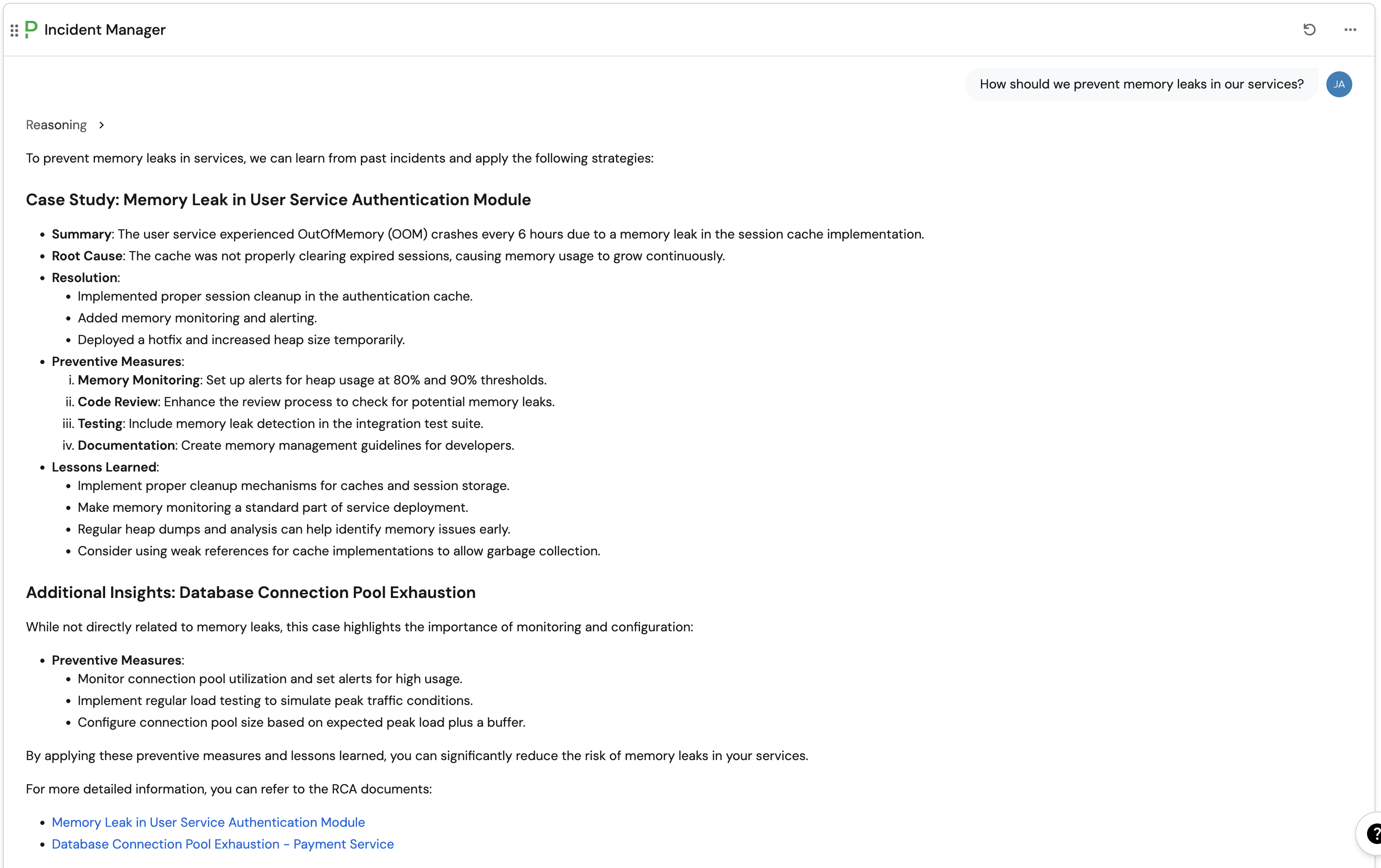
Have AI assist with building resilience
Whether it's finding out about incident resolution trends, or discovering more about current on-call assignments and active incidents, an AI Incident Manager Agent can help you.
Resilience depends on clear ownership. Make sure every service and component in your catalog has an owner—otherwise, incidents will fall through the cracks.
Enable easy on-call schedule management
Weddings, sick days, births and more can disrupt the uncreatively assigned rotas from your paging tools. Making the on-call roster visible and easy to update, is a key first stp in preparing for an incident.
Learn: close the loop
After every incident, use Port to capture what happened, analyze root causes, and update your processes. Continuous learning is the secret to long-term resilience.
Real-world benefits
- Fewer incidents: Proactive checks and clear ownership prevent problems before they start.
- Faster recovery: When incidents do happen, you know exactly who to call and what to fix.
- Continuous improvement: Every incident makes your system stronger.